
Marketing
Step beyond the everyday. Use smart algorithms to predict trends, pinpoint high-performing strategies, and understand where to focus on next, all backed by data.
Think, A-I can.
Few people understand AI like we do. And we’re here to
make AI work better for you.
WE’LL HELP YOU GROW YOUR BUSINESS
We work with clients to uncover hidden gems in data, helping you grow your business in an automated, efficient way.
Step beyond the everyday. Use smart algorithms to predict trends, pinpoint high-performing strategies, and understand where to focus on next, all backed by data.
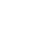
See what’s making your customers buy. And use the fresh insights to drive more sales or build accurate forecasts (all without an Excel spreadsheet in sight).

Predict customer behavior and know what they need, even before they do. Then analyze feedback in minutes to improve support, avoid frustration, and reduce churn.

Ease the burden on your employees, and forecast demand based on actual consumer needs. Launch offers and promotions at the right time and respect the Earth by minimizing product wastage.

Transform the healthcare landscape by harnessing the power of AI. Enhance diagnostics, optimize treatment plans, and streamline patient monitoring to deliver personalized care, improve outcomes, and transform the healthcare experience.

Harness the power of AI to bridge knowledge gaps and promote equitable access to education. Foster personalized learning experiences, enhance student engagement, and streamline educational administration.

Make your accounting team happy. Automate invoice processing, document flow, or tax returns, increasing overall accuracy while reducing manual work.

Optimize your processes. Shorten production times, reduce workload, and predict anomalies, all while detecting product defects and delivering unmatched quality.
WHAT YOU GET WHEN YOU WORK WITH OUR
AI SOFTWARE COMPANY
Our AI experts will process your data and study your needs. We’ll then transform your processes to make your business more efficient. With a tailor-made AI solution spurring you on, you’ll start to exceed expectations — with the DLabs team there to lend extra support, as and when needed.
UNIQUE EXPERTISE
We offer a rare combination of data science and software engineers, each fluent in neural networks, machine learning, and natural language processing. And we’ll work with your team, first to understand your needs, then get the most out of your data.
YOUR OWN AI SOFTWARE
We build products with your business in mind, meaning it integrates with your systems and starts generating results within weeks. Stop relying on just another widely available system and gain an edge over the competition.
AIR-TIGHT SECURITY
Data security is paramount in business. When you work with DLabs.AI, your data stays yours — even as we mine it, build products around it, and train our algorithms to solve your problems with ever-improving results.
A LOAD OFF YOUR SHOULDERS
We’re here to make your life easier and your business more efficient. We do that by optimizing workflows, helping you spend less time on repetitive tasks, and providing more value for your team and, most importantly, your customers.
DEVELOP AN APPLICATION WITH AI IN MIND
If you want to develop a product but you’re not sure you need AI, don’t worry. Our approach makes applications
AI-ready, leaving you to integrate AI whenever you want.
HERE’S WHAT WE KNOW
Our team is a mix of domain experts. After all, a product is only as good as the people who build it,
which is why DLabs.AI comprises people who specialize in their field.

Take machine learning one step further, uncovering unique insights in unstructured data.

Analyze free-form text, glean insights hidden in words, or classify and tag documents in seconds.

Emotion detection in images, ball-tracking in sport, even Face ID: it’s all computer vision.

Hand over mundane tasks to a computer, freeing your people to focus on what’s important.

Use sales history to create accurate forecasts or optimize your marketing with campaign analysis.

Train an algorithm to create hyper-targeted ads, spot trends, detect spam, and predict sales cycles.

Ever asked Alexa a question? Thank cognitive computing for her on-point, human-like answer.

Use self-learning networks to find valuable insights in complex, seemingly unrelated data sets.

Employ models such as GPT, LLama, or PaLM to empower machines with conversational capabilities eerily reminiscent of human interactions.

From creating captivating content and producing fascinating videos to crafting harmonious sounds, AI transcends boundaries in content generation.
DEMAND FORECASTING AND COST OPTIMIZATION
A scalable and 100% reusable cloud solution that simplifies decision-making processes for 8,000 shops (supported with explainable models), reduces food waste and increases revenue.
COST OPTIMISATIONS OF ~38%
Simpler tax returns
Using machine learning and neural networks, we helped Taxando reduce the time taken on this mundane task from 5 minutes down to a few seconds.
Predictive insights
A solution that automatically detects the most engaging content from across the web for any given category based on a defined taxonomy.
The aim of the project was to demonstrate the relationship between user content engagement and its semantic, syntactic features.

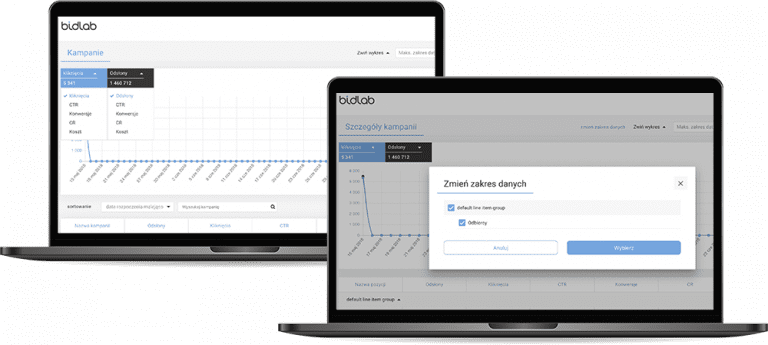
Marketing Data Dashboard
A web application dashboard that presents data from online marketing campaigns run on different platforms (inc. Facebook, Google AdWords, BDM, Adfrom).
The tool helps simplify reporting for BidLab clients.
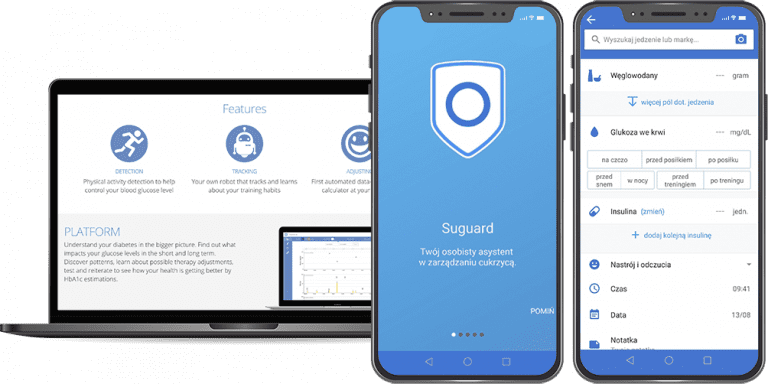
Mobile app for people with 1 type diabetes
Suguard is a comprehensive mobile application that uses state-of-the-art AI to personalize diabetic therapy and help patients in their everyday management of this chronic disease.
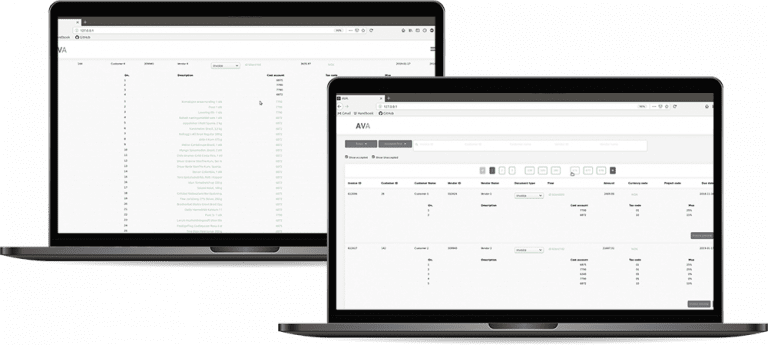
Invoice reconciliation
A platform that automates the process of invoice reconciliation.
The tool removed the manual effort involved in classifying invoices, helping the accounting department better track costs.


INDUSTRY SPECIALISTS RECOGNIZE OUR DOMAIN EXPERTISE
Technology-focused Clutch uses real-life reviews to identify the best in their field. DLabs.AI has won two separate Clutch awards, first in 2019 and again in 2020, proving our clients continue to love the products we build.
OUR CLIENTS PUT IT BEST
Nothing really matters if our clients aren’t happy. Thankfully, we’ve managed to please every single one,
as you can see below.




